NWChemEx Ecosystem
In this section we spec out the use cases for NWChemEx and how it fits into the broader computational chemistry ecosystem.
NWChemEx Use Cases
Generally speaking we see NWChemEx being used for:
electronic structure calculations on the largest supercomputers in the world
day-to-day electronic structure calculations
as part of high-throughput workflows
as a research platform for developing new theories
At this stage of design we are not concerned with capabilities (e.g. single-point energies, thermodynamic analysis, molecular dynamics) those will be handled at a lower level of design. Rather we’re interested in what sort of design requirements need to be built into the highest level APIs. From these use cases we can establish the following concerns:
performance (needed to make running on supercomputers worthwhile)
high-quality linear algebra (electronic structure involves lots of linear algebra)
ease of use (too high of a barrier will inhibit use cases where there are other choices)
library instead of program mentality (we shouldn’t assume we are driving the workflow)
extensibility (adding new theories should be easy)
varying levels of programming expertise (research is done by undergraduates, graduates, post docs, scientists/professors from a multitude of backgrounds)
These concerns are not orthogonal (for example ease of use and varying levels of programming expertise are related).
Overall Software Ecosystem
The following figure serves as a brief introduction to how NWChemEx addresses the aforementioned concerns as an organization, how the key pieces of the NWChemEx design fit together, and how the NWChemEx organization fits into the broader software ecosystem.
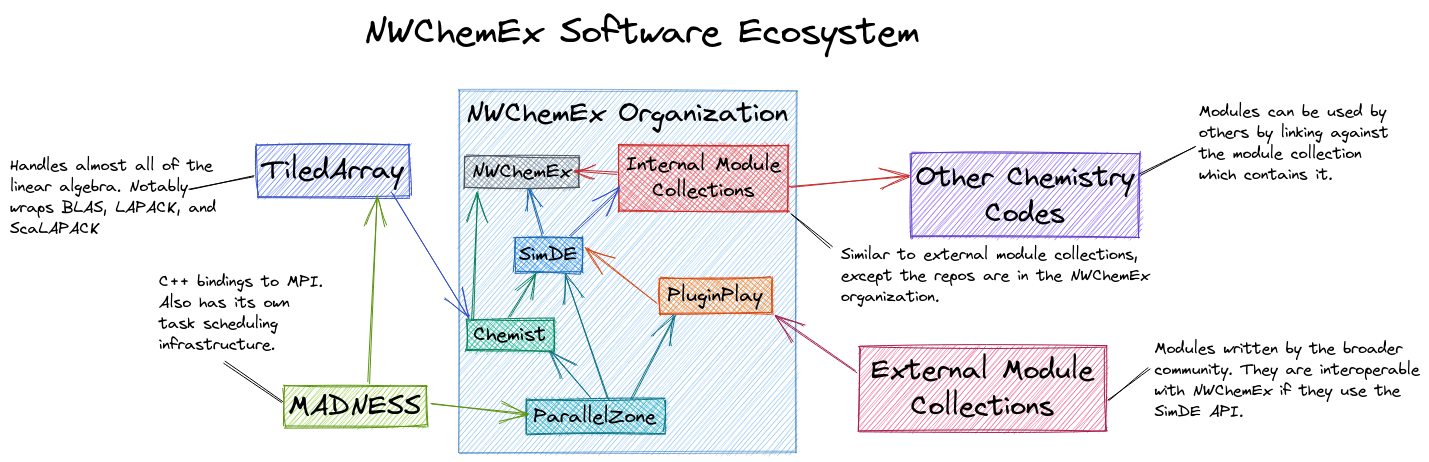
Fig. 1 Coarse overview of the NWChemEx software stack and its connections to other key stake holders in the broader community.
As a disclaimer, this figure is very coarse. A lot of the stack’s complexity is swept up into each of the boxes (particularly the “Internal Module Collections” box, which includes pretty much every electronic structure method that NWChemEx supports).
Performance key points:
Internal components of NWChemEx written in C++ to take advantage of the growing HPC support for C++ and to provide developers a performance focused coding language.
Performance is treated as a fundamental concern entering into the stack as part of the low level ParallelZone component.
ParallelZone acts as a sort of domain-specific language (DSL) for the rest of the NWChemEx stack, abstracting away much of the implementation details
Much of the actual scheduling, data movement, etc. is handled by the externally maintained MADNESS runtime and the libraries underlying it.
Linear algebra key points:
Linear algebra is the among the second lowest components of the stack, entering via Chemist.
Like ParallelZone, Chemist provides abstractions which allow the rest of the stack to express its linear algebra needs in a sort of DSL without worrying about the underlying details.
Efficient and performant linear algebra and tensor-related operations are provided by TiledArray.
Ease of use key points:
The tiered stack makes it easier to hide details.
The focus on DSLs at each layer lowers the barrier to entry as code looks more like what its modeling and less abstract.
Component mentality key points:
User facing APIs are written in Python to take advantage of its popularity in scientific software (particularly in workflows)
PluginPlay provides NWChemEx’s abstractions for interacting with software components.
The bulk of NWChemEx’s capabilities are provided by its internal module collection, which PluginPlay can run.
Other chemistry codes can link to any of our internal module collections and use any module in that collection.
Extensibility key points:
Developers outside the organization can write modules, which can then be immediately used with the NWChemEx software stack via PluginPlay.
Adding modules does not require modifying NWChemEx
Varying programmer expertise key points:
The focus on abstraction allows each layer to hide many of the technical details of the layer below it. These details are not lost, they are rolled up into opaque objects which get unrolled as they traverse the stack.
By time someone considers a layer like SimDE they are typically using objects like wavefunctions, molecules, and orbitals to express their computation rather than tensor ops or MPI calls.