PluginPlay Overview
The background section of the PluginPlay documentation is extensive. This is because PluginPlay is targeted at scientific research software and thus it is important to understand the scientific merits of PluginPlay and how it relates to other software. That said, most users can safely ignore most of the content in the background section, and this overview page is designed to give you the essentials in about a 5 minute read.
What is PluginPlay?
There is a need for modular scientific software. Using PluginPlay, developers write algorithms inside self-contained Module objects. Software packages are then created by “wiring” Module objects together. As additional Module objects are developed and as new methods and properties are derived, the ecosystem of Module objects grows, and the cycle repeats. PluginPlay facilitates writing sustainable modular scientific software packages by providing a framework that is focused on enabling dynamic:
The dynamic nature of the resulting package makes it easier to extend the package to new use cases and new hardware. PluginPlay includes a number of other features designed to make development as easy as possible, e.g., tools for:
Who should use PluginPlay?
PluginPlay is meant as a framework on which to build a software package. PluginPlay is thus really targeted at developers who fall into two groups. The first group of developers actively write and maintain modular software package(s). The second group of developers write modules which can be consumed as plugins to the aforementioned modular software packages. Of course, these groups of developers need not be disjoint and developers may find themselves in both groups at one time or another.
While PluginPlay can be used as a workflow tool, its domain-agnostic nature can make standard workflow tasks cumbersome. So while end-users of a software package can (and should be able to) interact directly with PluginPlay, in many cases developers can serve their community better by wrapping the PluginPlay calls needed for domain-specific tasks in domain-specific API.
How does PluginPlay work?
The PluginPlay framework relies on four concepts:
Modules. These are components of the software. Aside from the inputs to the module and any hooks/callback locations the module provides, each module is a self-contained algorithm, typically with the granularity of a standard function.
Property types. When a module needs to call another module, they must do so through a registered API. Property types are these APIs.
Plugins. Related modules are typically distributed together. The distribution forms a plugin.
Module manager. The module manager is the runtime representation of the PluginPlay framework. Plugins, modules, and property types are registered with the module manager. In turn, the module manager dynamically assembles the program.
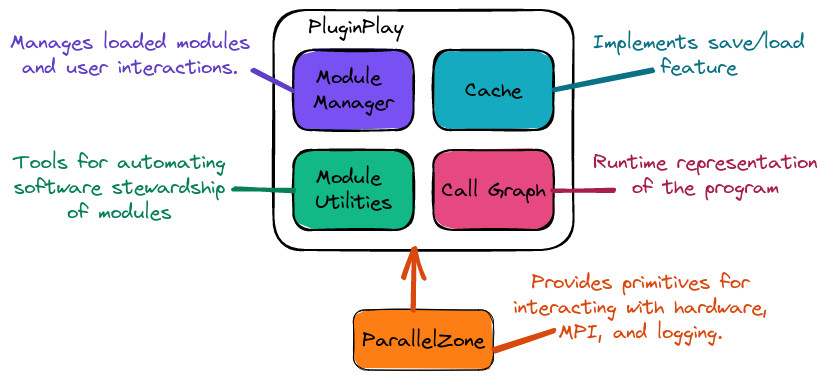
Fig. 1 High-level architecture of PluginPlay. Users primarily interact with PluginPlay through the module manager. The module manager builds the call graph representation of the program. When users run the program, results are stored in the cache, and developers can write new modules using the module utilities.
Fig. 1 is a simplified architecture diagram of PluginPlay. The point of the diagram is to give you a very rough idea of what goes on inside PluginPlay so you can rationalize about its behavior. For performance reasons PluginPlay is substantially more complicated than this diagram suggests.
At the bottom of the diagram is PluginPlay’s primary dependency, ParallelZone. PluginPlay is very concerned with performance and ParallelZone is used for inspecting available hardware, scheduling tasks, and logging program progress. ParallelZone is exposed to module developers, who in turn may use ParallelZone directly or may initialize their own runtime systems from ParallelZone.
Conceptually PluginPlay’s internals are comprised of four main parts. The simplest is the module manager, which is where modules and property types are registered. When the time comes to assemble a program, the contents of the module manager are used to populate a call graph. The nodes of the call graph are taken from the list of registered modules and the property types are used to form the edges between the nodes/modules. When the program is actually run the computed results are cached to facilitate checkpoint/restart and for performance reasons, e.g., avoiding redundant computations. The last part of PluginPlay is a collection of utilities which makes it easier for module developers to develop high-quality modules, e.g., documentation generators, and debugging tools.