Designing RAM Class
As stated in Designing ParallelZone’s Parallel Runtime we need abstractions to represent
the physical hardware resources on the computer. The RAM class models
the random-access memory of a node.
Why Do We Need the RAM Class?
From the perspective of ParallelZone, the RAM class is primarily envisioned
as a means for users to specify the start/end points of one-to-all and
all-to-one MPI operations. End users can also use the RAM class to
figure out how much memory the process has access to, which can be useful for
selecting among algorithms (space-time trade-off).
Design Considerations
Including the considerations brought up in Designing ParallelZone’s Parallel Runtime and
Designing ParallelZone’s ResourceSet Class we see the RAM class needing to consider:
Current “state”
Total capacity
Total free memory
Total used memory
Potentially the transfer rate
All-to-one and one-to-all MPI operations
Encapsulation of details
Automatic tracking of memory usage
Architecture of the RAM Class
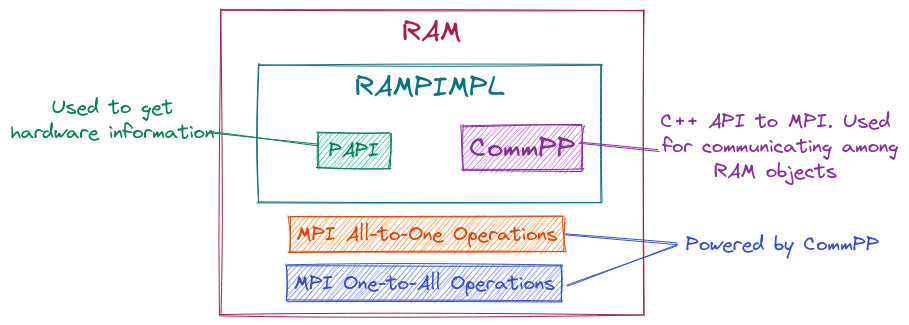
Fig. 9 High-level architecture of the RAM class.
Fig. 9 illustrates the main pieces of the RAM class. These
pieces address the concerns by:
We use the PAPI runtime system for accessing information about the
RAMA
CommPPobject is used for the MPI operations.The use of the PIMPL idiom allows us to avoid leaking PAPI or the
CommPPobject through the API.This issue has not been resolved, but could be done through a custom allocator class tied to the
RAMobject.
Proposed APIs
Examples of all-to-one communication with ParallelZone.
auto rt = get_runtime();
// Each resource set generates some data
auto data = generate_data();
// This gathers the data from all members of rt to resource set 0
// Type U is deducible from type of data w/ template meta-programming
std::optional<U> output = rt.at(0).ram().gather(data);
if(output.has_value()){
// This only gets run on rank 0
// Do stuff with output
}
// Reductions are similar, but take an op to apply
auto op = get_op_to_apply();
// Similar to gather, this reduces the data down to rank 0's RAM
// Type V is deducible from type of op w/ template meta-programming
std::optional<V> output2 = rt.at(0).ram().reduce(data, op);
if(output2.has_value()){
// This only gets run on rank 0
// Do stuff with output2
}
Examples of one-to-all communications
auto rt = get_runtime();
auto data;
if(me == rt.at(0)){
data = fill_in_data();
}
// Value of data is ignored for ranks not equal to 0
auto output = rt.at(0).ram().scatter(data);
Examples of one-to-one communications
auto rt = get_runtime();
std::optional<decltype(fill_in_data())> data;
if(me == rt.at(0)){
data.emplace(fill_in_data());
}
// Sends the data to rank 1, type U determined by template meta-programming
std::optional<U> output = rt.at(1).ram().send(data, "some tag");
if(output.has_value()){
// This part is only run by rank 1
// Do stuff with output
}
The proposed APIs admittedly have some MIMD aspects to them in the “if I’m root” logic. This could be hidden in a scheduler. Something like:
auto future_2_data = rt.schedule([](){return fill_in_data();});
With the idea being the underlying scheduler chooses the root.
Additional Notes
The RAM class is presently a stub. In particular PAPI is not hooked up.