Designing RuntimeView Class
The need for the RuntimeView class grew out of
Designing ParallelZone’s Parallel Runtime. Here we flesh the design out more.
Why Do We Need the RuntimeView Class?
As discussed in Designing ParallelZone’s Parallel Runtime, the RuntimeView class is
ParallelZone’s abstraction for modeling the runtime environment. RuntimeView
will also serve as the top-level API for accessing ParallelZone
functionality.
What Should the RuntimeView Class Manage?
ParallelZone assumes it is managing the runtime environment for a potentially multi-process program. In general that program can be running on a laptop, the number one supercomputer in the world, or anything in between.
RuntimeViewis a view of the runtime environment at the highest level. System-wide state will be accessible fromRuntimeView. State includes:System-wide scheduling
System-wide printing
Processes
Hardware
Multi-process operations need to go through
RuntimeView.MPI compatibility.
Flexibility of backend.
Setup/teardown of parallel resources
See Understanding Runtime Initialization/Finalization for more details, but basically we need callbacks.
RuntimeView Architecture
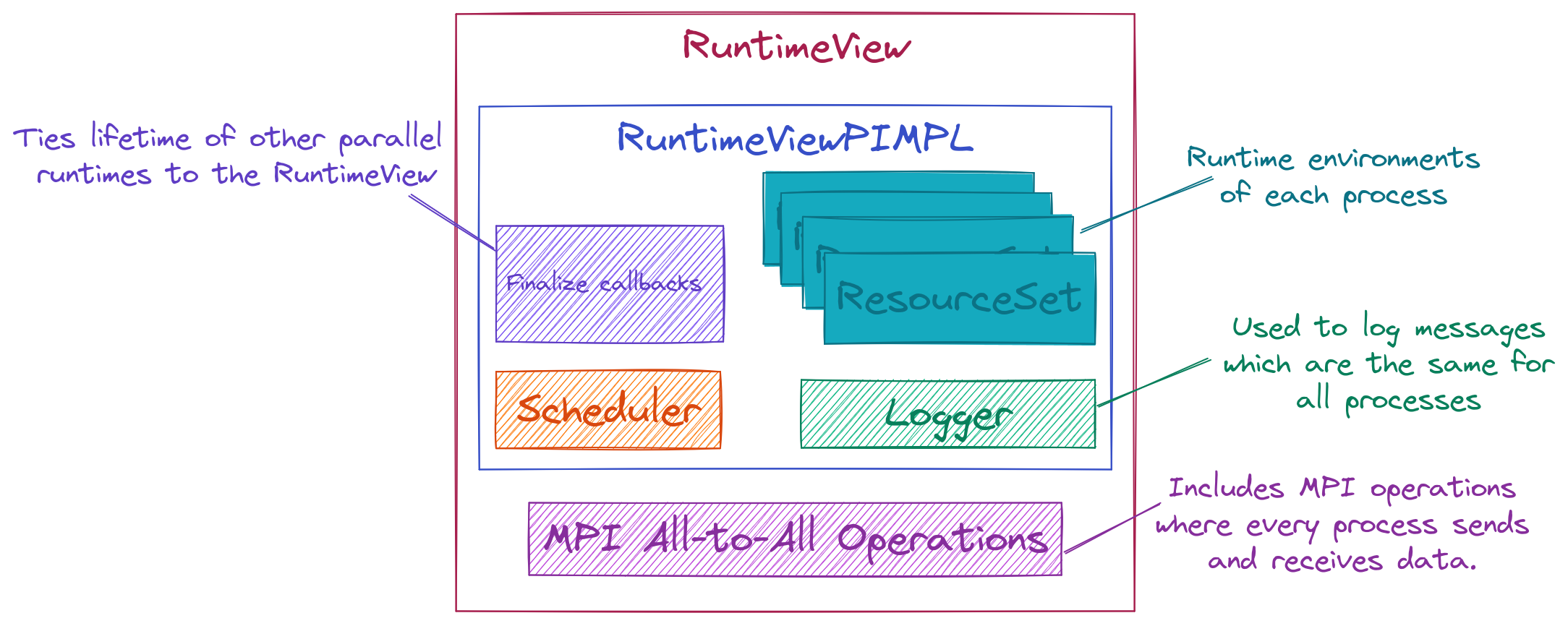
Fig. 7 Schematic illustration of the RuntimeView class and its major pieces.
The architecture of RuntimeView is shown in Fig. 7. This
addresses the above consideration by (numbering is from above):
Introducing components for each piece of state. Process to component affinity is maintained by
ResourceSetobjects.Exposing MPI All-to-All operations at the
RuntimeViewlevel.MPI All-to-One and One-to-All Operations are delegated to
RAMandGPUobjects in a particularResourceSet.This facilitates selecting start/end points.
MPI support happens via the
CommPPclass.The use of the PIMPL design allows us to hide many of the backend types. It also facilitates writing an implementation for a different backend down the line (although the API would need to change too).
Storing of callbacks allows us to tie the lifetime of the
RuntimeViewto the teardown of parallel resources, i.e.,RuntimeViewwill automatically finalize any parallel resources which depend onRuntimeViewbefore finalizing itself.Note, finalization callbacks are stored in a stack to ensure a controlled teardown order as is usually needed for libraries with initialize/finalize functions.
Some finer points:
The scheduler is envisioned as taking task graphs and scheduling them in a distributed and threaded manner. The latter relies on collaboration with
ResourceSetinstances.The Logger is an instance that every process can access. It represents the authoritative printing of the program. It’s exact behavior should be customizable, but it is assumed this logger is always called in a SIMD manner by all processes. Default behavior is to redirect all output to
/dev/nullexcept that of the root process.
Proposed APIs
Examples of all-to-all communications:
auto rt = get_runtime();
auto data = generate_data();
// This is an all gather
auto output = rt.gather(data);
// This is an all reduce
auto output2 = rt.reduce(data, op);
Example of tying another library’s parallel runtime teardown to the lifetime of
a RuntimeView (note this is only relevant when ParallelZone starts MPI):
// Create a RuntimeView object
RuntimeView rt;
// Initialize the other library
other_library_initialize();
// Register the corresponding finalization routine with the RuntimeView
rt.stack_callback(other_library_finalize);
Note
As written the APIs assume the data is going to/from RAM. If we eventually want to support other memory spaces we could create overloads which take the target space. In particular we note that we can NOT do things like:
auto output = rt.my_resource_set().ram().gather(data);
because that would result in deadlock (it calls a series of all-to-one calls where each rank thinks it’s the root).