Designing the Module Component
The Designing the Call Graph Component section motivated the need for a module component (although the fact that we’ve written “module” like a thousand times by now ought to have suggested it too…).
What is the Module Component?
See Module for PluginPlay’s definition of a module. The module component is primarily responsible for interfacing PluginPlay to the algorithm the module developer wrote.
Module Component Considerations
- User interface.
Stemming from Designing the Call Graph Component, one of the motivating factors for the module component is to provide a mechanism for a user to interface their algorithm with PluginPlay.
- Memoization.
Also stemming from Designing the Call Graph Component, caching/memoization of a module is the responsibility of the module component.
Ideally largely automated
Developers may need mark modules as incapable of being memoized when they are not sufficiently “pure” (i.e., they have side effects, are non-deterministic, and/or depend on global input).
- Have a construction phase.
Modules will ultimately be classes. The construction phase will happen in the constructor and may include:
Used by developer to register the module’s metadata.
Also can initialize constant state needed by the module.
- Expose a
runhook. As agreed upon in Designing the Call Graph Component, executing a module happens by calling a
runmember. Members of the module component must expose such a member.The
runmember should contain minimal branching. Traditional if/else logic needed for determining what function to run should be handled by selecting submodules ahead of time.
- Store callback points.
The graph only works if nodes can call other nodes. Modules must be able to call sub-modules, which requires somehow being able to hold the submodules.
- Driver modules.
Motivation for driver modules is given below. In short, we need modules whose sole purpose is to do some setup and then call another/other module(s).
Need for Driver Modules
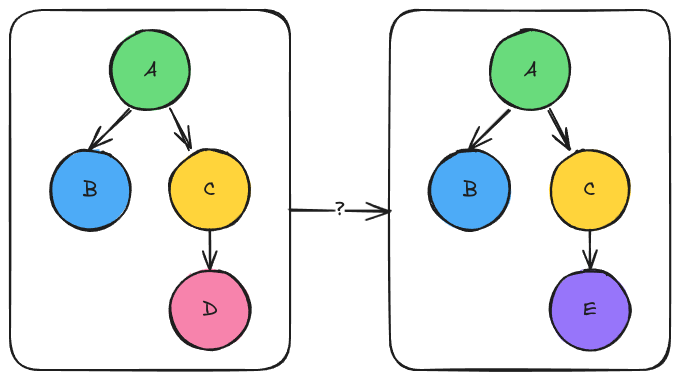
Fig. 6 Left the original graph. Right the graph resulting from using module “E”
instead of “D”. The question is how can both graphs be loaded into the
ModuleManager simultaneously?
Consider the two graphs shown in Fig. 6. Let’s call
the left graph “L” and the right graph “R”. If we choose to have graph “L” be
the default graph that is loaded into the ModuleManager the user can go
from graph “L” to graph “R” by telling the ModuleManager to switch the
submodule node “C” uses from node “D” to node “E”. While viable, this is not
necessarily user-friendly as running “R” vs “L” means the user needs to know to
switch “D” to “E”.
If we wanted to make it easy to run both “R” and “L” one option is to make
copies of the “A” and “C” modules. Let “RA” and “RC” respectively be those
copies. Then it becomes possible to have both the “L” and “R” graphs loaded into
the ModuleManager by default. More specifically, “L” is loaded in in the
same manner, “R” is loaded in by having “RC” call “E” and “RA” call “B” and
“RC”. While this solution works, it can be tedious depending on how nested
the graph is. It also can be wasteful because the two graphs may have a
substantial amount of overlap.
Module Component Design
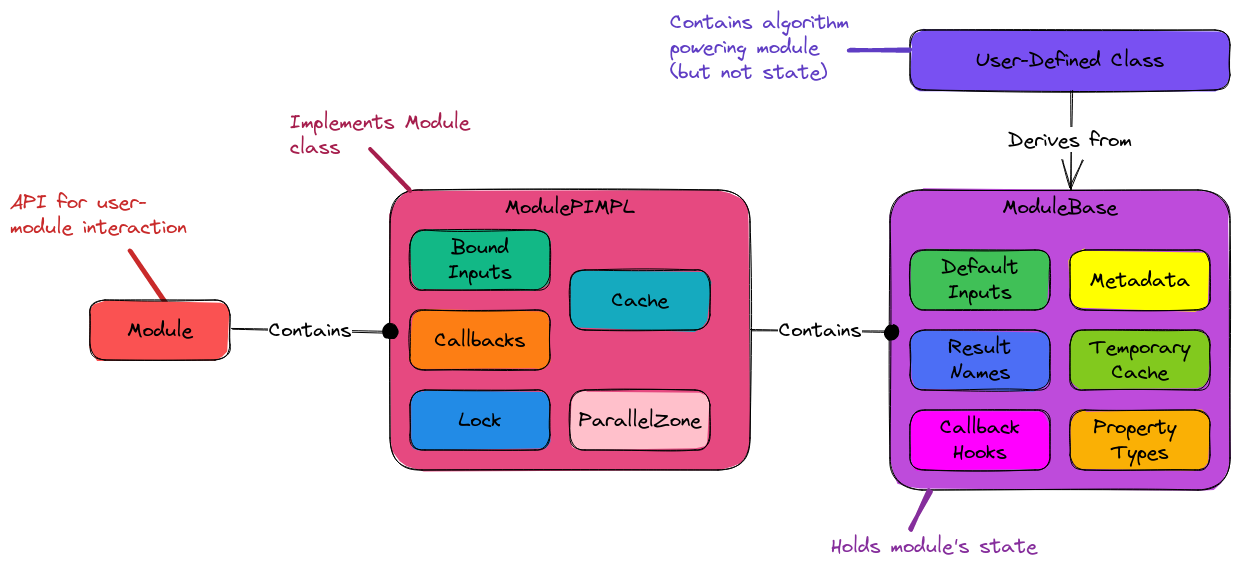
Fig. 7 Module component design showing the contact points. Users of the
module go through the Module class API. PluginPlay interacts with
the user of the module via the ModulePIMPL class and the module developer
via the ModuleBase class. Module developers interact with the component
by deriving from ModuleBase.
The design of the module component is shown in Fig Fig. 7. The subsections below go over the major pieces in more detail.
Module Development
Following traditional object-oriented practices module developers implement
modules by deriving from the ModuleBase class. In the constructor of their
module, module developers set the property type(s) their module satisfies,
any additional inputs/results (beyond those specified by the property type),
callback hooks used throughout, and the metadata (version, author, papers to
cite, etc.). The actual state provided in the constructor is stored in the
ModuleBase part of the object and preserved in the state provided. When
users change inputs, or callbacks the user’s requests are actually stored in
the ModulePIMPL.
The other half of implementing a module is done when the module developer
overrides the run_() member. This member is assumed to be a pure function
(a pure function always returns the same results for the same inputs, and has
no side-effects). PluginPlay helps enforce this assumption by making the
run_() member const. The need for a pure function is brought on by the
desired black-box nature and for memoization purposes. To be treated as a black
box the module must receive no “hidden” inputs including from global variables,
files, or state not registered with PluginPlay. In practice, particularly when
considering modules meant to be called iteratively, a module may need access
to modifiable state. This is where the “Temporary Cache” comes in. The derived
class is able to put/get data in/out of the temporary cache using a key-value
system.
Driver Module Development
To address Driver modules. we introduce the idea of a driver module.
Design 1.0
Note
This is here for historic context, it’s NOT current.
To ensure that driver modules interoperate with other modules, driver modules
also inherit from ModuleBase. Keeping with Expose a run hook., we want the
run member of the driver module to have minimal branching, thus logic for
swapping modules should happen before run is called. Our solution is to
introduce ModuleBase::pre_run. This method allows the derived module to
manipulate the input values and submodules run will call before they are
passed to run. By default ModuleBase::pre_run will just return the
inputs and submodules provided to it. To define a driver module, the module
developer overrides the default implementation. For symmetry we also introduce
ModuleBase::post_run which allows the derived class to manipulate the
results before they are given back to the caller of Module::run.
The official C++ API for declaring a module is to use the DECLARE_MODULE
macro. If the user is going to override pre_run or post_run this changes
the declaration needed (i.e., the signature for pre_run and/or post_run
must be part of the declaration). To avoid an API break we introduce a new macro
DECLARE_MODULE_DRIVER, for symmetry we require users to override both
pre_run and post_run if they choose to write a driver (even if they
only need one or the other).
Design 2.0
In prototyping design 1.0, it was realized that Module::run looks like:
std::tie(inputs, submods) = module.pre_run(inputs, submods);
auto rv = module.run(inputs, submods);
rv = module.post_run(inputs, submods, rv);
With nothing between pre_run and run (or run and post_run) there
is no reason (aside from partitioning preference) why the module developer can’t
just put their pre-run and post-run logic inside their module’s run overload.
More specifically the same inputs and submods that would go to pre_run can
just be fed to run, then the same logic which would have happened in
pre_run can just happen in run. Similarly all information which would
have been fed into post_run is also available in run.
Ultimately, it was thus realized that pre- and post- conditions can be handled as is.
Summary
The above design specifically addresses the stated considerations by:
Module developers inherit from
ModuleBaseand fill in the virtualrun_member.Metadata for the module can be registered with
ModuleBase(and thus PluginPlay) in the derived class’s ctor.
ModulePIMPLperforms memoization.
Derived classes use their constructor to set meta-data.
Moduleexposes therun(and more usefulrun_as) which executes the module.
ModuleBaserecords the hooks (property types and associated tag) for each call back location.
ModulePIMPlholds the bound callbacks for each hook.
Driver modules can be